特工观察|GLM-4.5:智能体任务主导下的国产大模型路线探索_
GLM-4.5 不是又一款“国产 GPT 替代品”,而是一块“能执行、能调度、能构建系统”的结构智能地基。
近两天,智谱 GLM 系列迎来最新成员 —— GLM-4.5 与 GLM-4.5-Air。相比以往的“大模型发布潮”,这次更新并未强调规模扩张,反而在参数更精简的前提下,以“原生智能体能力融合”为核心,重构模型结构、训练策略与应用场景。
GLM-4.5 拥有 3550 亿总参数和 320 亿激活参数,而 GLM-4.5-Air 拥有 1060 亿总参数和 120 亿激活参数。
作为观察者与体验者,特工们将从技术原理与表现能力出发,拆解这款国产模型能否在推理、编程与工具调度三大核心维度上站稳脚跟。
任务融合的模型范式:推理 × 编码 × Agent
过去的大模型通常各有所长:有的擅长聊天对话,有的专攻编程推理,还有的在 Agent 调度方面表现突出。但在实际应用中,用户往往希望一个模型能够同时理解复杂任务、调度工具并生成结构化结果。GLM-4.5 正是在这样的背景下诞生的统一模型。
它提供高达 128k 的上下文长度、原生函数调用能力,能直接在推理中调度浏览器、代码执行器等外部工具。相比传统通过 prompt 组合脚本实现 Agent 功能的方案,GLM-4.5 在模型结构中就完成了智能体能力的融合训练,具备更强的一致性与可靠性。
在智能体任务(τ-Bench、BFCL、BrowseComp)、复杂推理(AIME、GPQA、HLE)和编程能力(SWE-Bench、Terminal-Bench、CC-Bench)等 12 项主流测试中,GLM-4.5 均有稳定表现:
横向对比四项主流 Agent Benchmark,可以看到 GLM-4.5 在大多数任务上均处于第一梯队,在需要结构理解与工具组合能力的场景中得分更高。这表明其“原生 Agent 能力融合”的路线,已经在系统智能主赛道中展现出现实竞争力。
尤其在网页浏览类 Agent 基准 BrowseComp 上,GLM-4.5 的准确率达 26.4%,远超 Claude-4-Opus(18.8%),逼近 GPT-4o(28.3%),展现出在网页理解、内容提取、行为执行等一体化任务中的强执行能力。
同时,从 BrowseComp 的算力表现曲线来看,GLM-4.5 在算力-性能比上也更优:在相似推理资源投入下取得更高的准确率,说明其底层设计在推理效率与资源使用之间实现了良好平衡。
从编程任务中的两项权威评测指标来看,GLM-4.5 在 SWE-bench Verified 任务中得分为 64.2,位列开源模型前列,仅次于 Claude-4 系列、o3 与 Kimi K2,优于 GPT-4.1,说明其具备强大的代码理解与修复能力。而在注重执行与交互的 Terminal-Bench 中,GLM-4.5 同样超过 GPT-4.1 与 Claude-4 Sonnet,在实际工程指令链处理上的表现更加平衡。
具体来看,在 Agent 编程任务中,GLM-4.5 的平均工具调用成功率超过 90%,在已参与对比测试的主流模型中表现优异。
从以下 Case 可以直接体现其支持多轮对话构建网页产品、拖拽式看板、小游戏等,同时具备结构代码补全、交互功能优化、多轮交付的能力:
TODO 看板构建任务:用户用一句话描述需求,模型自动生成可用的任务管理网页 - https://chat.z.ai/s/b262f532-7b4d-4ed3-9a94-c9afad9f59c1
小游戏生成任务(Flappy Bird):模型独立完成游戏逻辑和前端代码,生成完整 HTML5 游戏 - https://chat.z.ai/s/2a9a1a90-545b-4f29-b6ac-854539dcc323
结构化 SVG 动画生成任务:根据指令生成带动画效果的 SVG 图形,可调节速度与样式 - https://chat.z.ai/s/6e4c7742-7a2d-469f-9dee-b1b35166efe4
模型架构与训练优化:瘦高设计 × 强化学习框架
GLM-4.5 在底层架构上采用了 MoE(专家混合)结构,搭配 loss-free balance 路由与 sigmoid gate 技术,在保证推理效率的同时提升稀疏激活能力。模型结构设计上延续“瘦高”路线,即减少宽度、增加深度,能显著提升推理表现。
它还引入了部分位置编码(partial RoPE)与 Grouped-Query Attention,注意力头数量提高至 96,在多项推理任务中表现稳定提升。优化器方面,GLM-4.5 采用 Muon 替代传统 AdamW,配合 QK-Norm 稳定训练过程,并引入 Multi Token Prediction(MTP)机制以加快生成速度。
训练路径上,模型先在 15T 通用语料与 7T 编程推理语料上进行预训练,随后在 500B 代码数据、500B 合成推理数据和 100B Agent 任务数据上进行中期训练,最大上下文窗口扩展至 128K,完成语言、推理与工具调度能力的深度融合。
为了训练具备复杂 Agent 行为的大模型,智谱团队构建了 slime 框架,专为大模型强化学习设计,支持异步环境收集与并行训练。它通过解耦训练与交互流程,提升数据吞吐与 GPU 利用效率,同时使用混合精度(FP8 推理 + BF16 训练)提升 roll-out 速度。
工程落地与多场景应用:从 API 到 Agent 交付
除了推理与编程,GLM-4.5 在 Agentic 内容生成方面也表现突出,包括演示文稿生成、海报排版、SVG 动画创作等。例如在 PPT 生成中,GLM-4.5 Agent 可自主检索图文内容、规划逻辑结构并自动生成图文混排页面,完成“上传文档—生成幻灯片—补图优化”全过程。
塔代伊·波加查尔的成就 PPT:输入人物关键词后,自动生成涵盖其职业生涯亮点的图文混排演示文稿。
https://chat.z.ai/s/e674f111-2f70-4df5-accc-98da4d498058
赛博朋克卡牌生成:生成多角色、带属性设定与图文排版的卡牌合集页面,串联“文案创作 + 数据结构构建 + 多模态调用”三方面的能力。
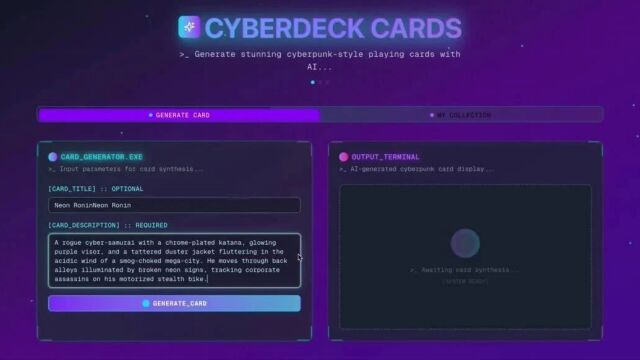
按住画面移动小窗
https://chat.z.ai/s/4b0d2f79-f4fa-4607-aadf-c4514bb594a8
在部署路径方面,GLM-4.5 明显比上一代产品更具工程友好性:
性能稳定、调用效率高:API 接口速度可达 100 tokens+/秒,支持并发调用与批量任务,响应速度在开源模型中表现稳健。
兼容性好:可无缝对接 Claude Code、Roo Code 等主流 Agent 框架,适配图文生成、搜索调度、多 Agent 协同等任务。
开放策略灵活:开发者可通过“V 你 50 ”计划(50 元/月不限量调用 API!)进行试用,适合小团队、原型验证与本地部署前线上评估。
成本优势显著:仅为 DeepSeek-R1 参数量的 1/2,Kimi-K2 参数量的1/3,调用价格低至每百万 tokens 输入 0.8 元、输出 2 元,适合大规模部署。
且 GLM-4.5 和 GLM-4.5-Air 的模型权重现已在 HuggingFace 与 ModelScope 全量开源,支持 vLLM、SGLang 等框架本地部署。
快速体验入口:
Z.ai 聊天体验:https://chat.z.ai
BigModel API 文档:https://docs.bigmodel.cn/cn/guide/models/text/glm-4.5
GitHub 源码与部署说明:https://github.com/zai-org/GLM-4.5
特工之思:国产 Agent 地基的突破性一跃
从这次 GLM-4.5 的发布能感觉到,国产大模型已经不再执着于“谁更大”“谁更快”的榜单争夺了,而是开始认真琢磨一件事:怎么让模型真正用起来、跑起来、干活儿。
过去两年,国产模型在参数规模和文本生成能力上持续突破,但整体仍以“语言生成”为核心能力。而 GLM-4.5 正在逐步打破这个瓶颈 -- 结构化输出、多工具调度、任务组织能力。
不过,能力边界在哪、不同任务下的稳定性如何、和国外最强模型还有多少差距.…这些问题都依然在。从系统架构到工程部署,GLM-4.5 至少迈出了一大步。
也许很快,当开发者和大众用户都普遍在用智谱自动跑业务、搭网页、调接口。那时候再看 GLM-4.5,会觉得它完全不只是版本号上的一次更新,而是能力范式的一次转向。